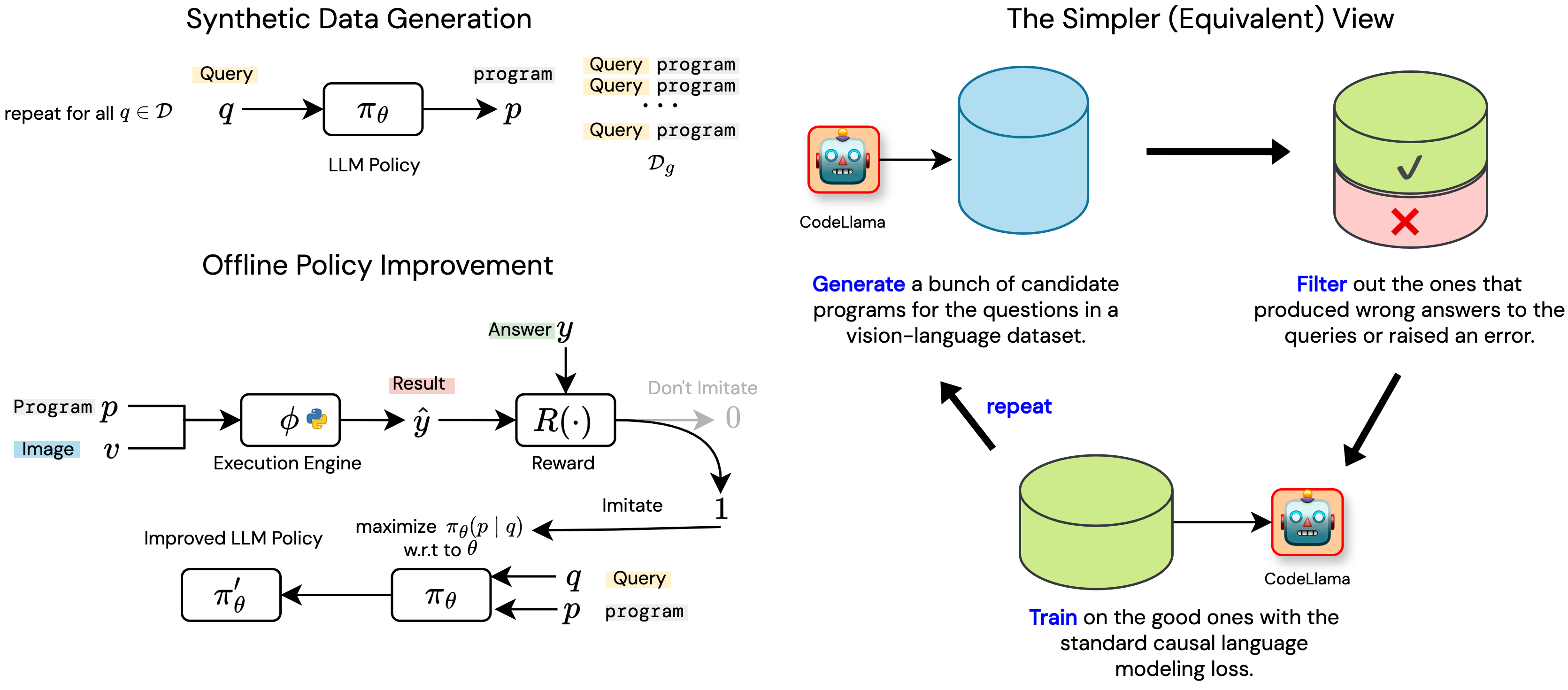
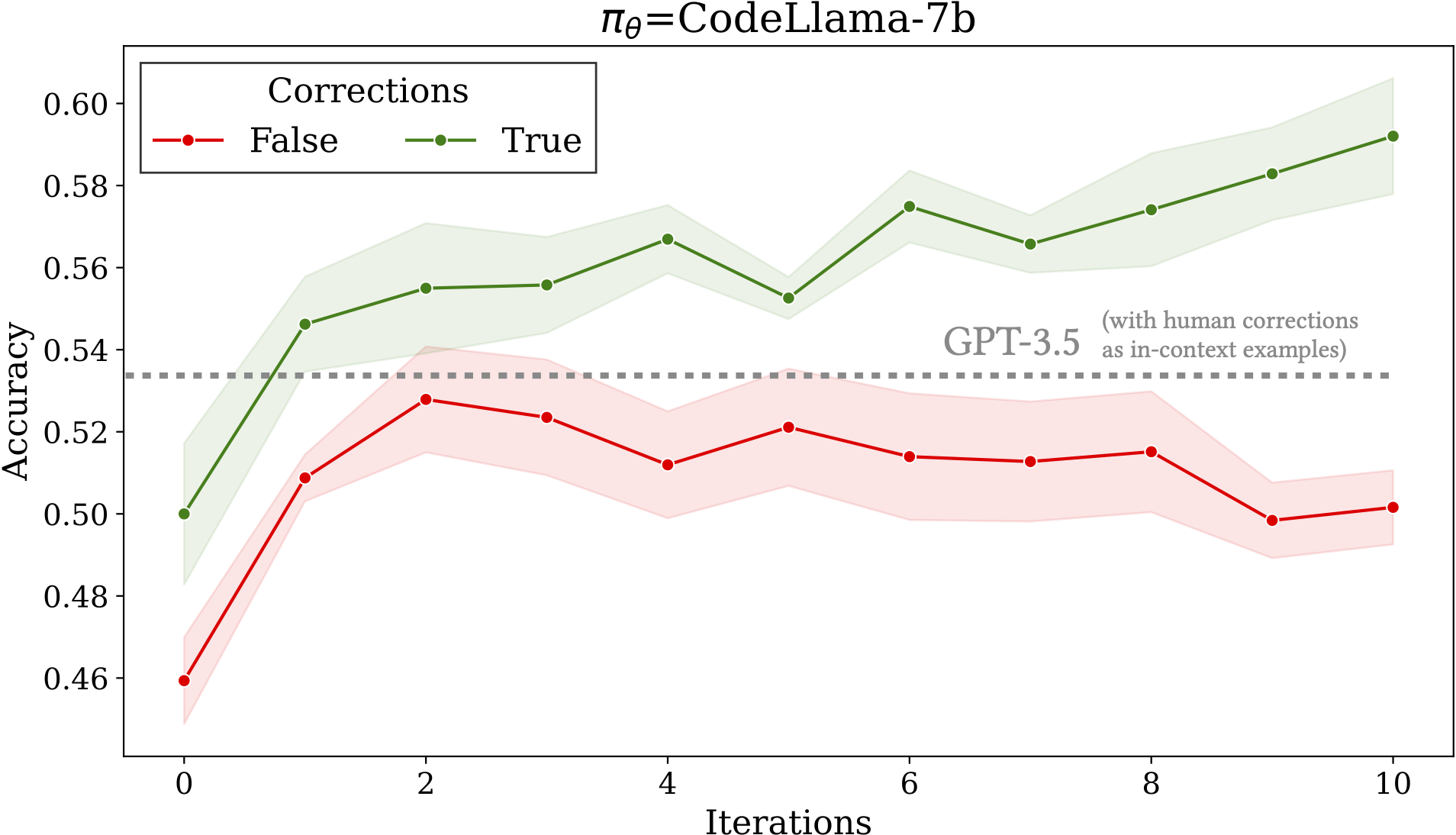
Is it possible to improve the visual program synthesis abilities of an open code LLM without using large scale human supervision or outputs from a strong commercial model?
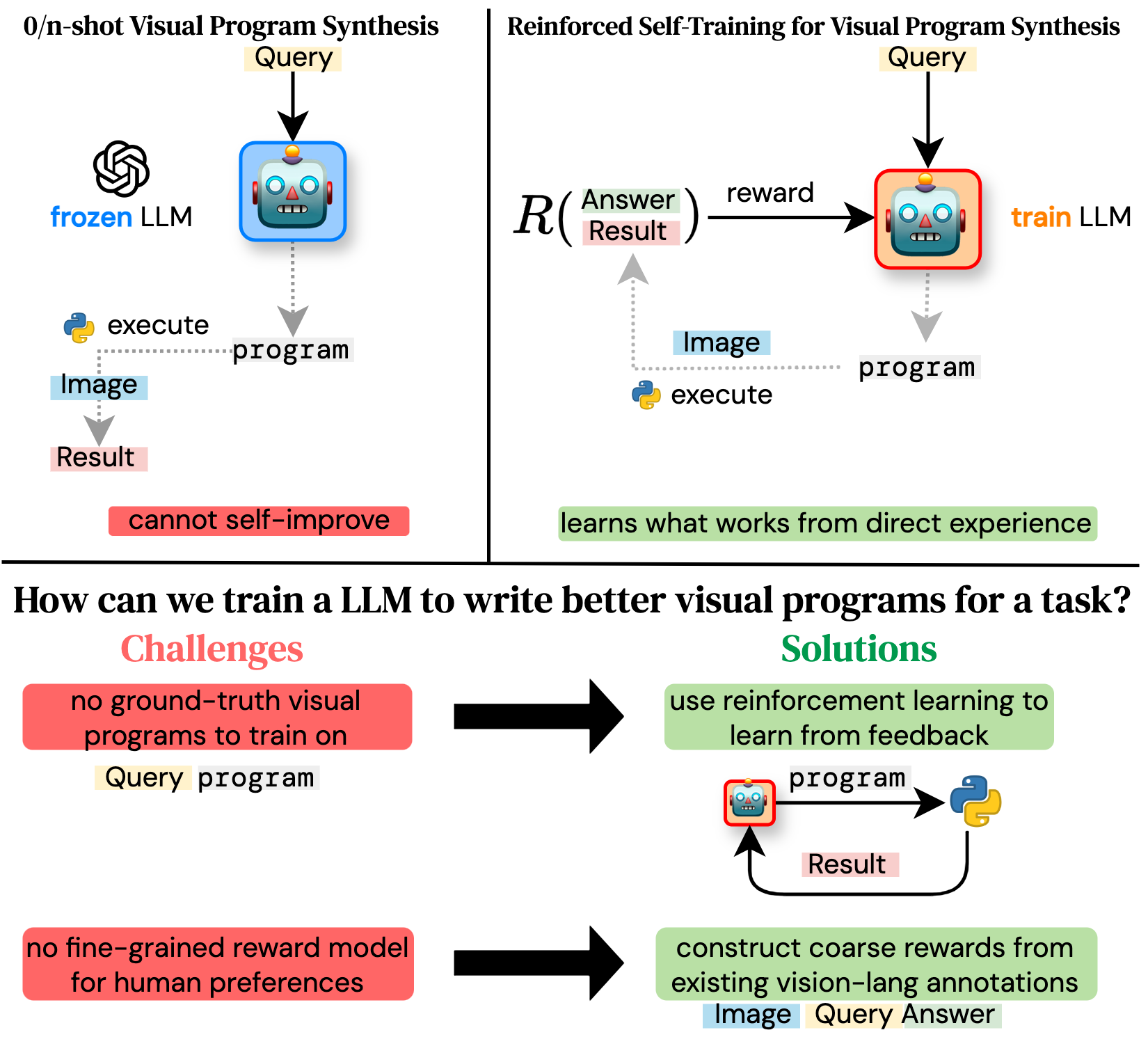
Python-based visual program synthesis asks a LLM to solve compositional computer vision tasks by writing Python code. Existing methods for visual program synthesis primarily use frozen, commercial LLMs (e.g. GPT-4) as program generators. We explore the idea of self-training with synthetic data and feedback from an interpreter to improve the visual program synthesis abilities of an open code LLM.