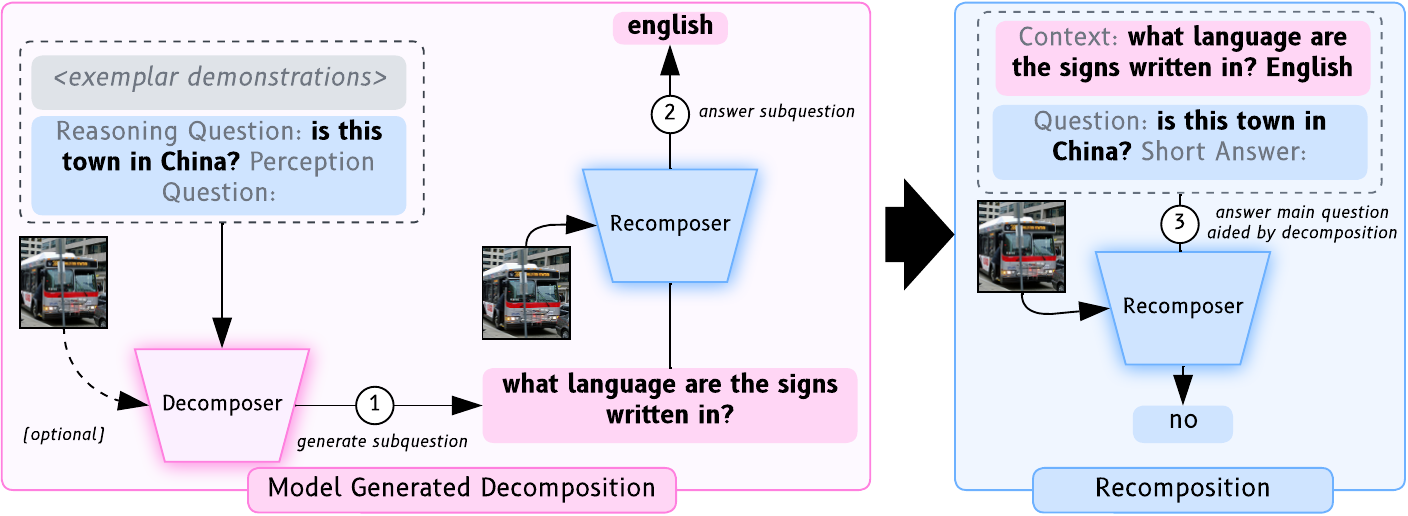
Visual question answering (VQA) has traditionally been treated as a single-step task where each question receives the same amount of effort, unlike natural human question-answering strategies. We explore a question decomposition strategy for VQA to overcome this limitation. We probe the ability of recently developed large vision-language models to use human-written decompositions and produce their own decompositions of visual questions, finding they are capable of learning both tasks from demonstrations alone.
However, we show that naive application of model-written decompositions can hurt performance. We introduce a model-driven selective decomposition approach for second-guessing predictions and correcting errors, and validate its effectiveness on eight VQA tasks across three domains, showing consistent improvements in accuracy, including improvements of 20% on medical VQA datasets and boosting the zero-shot performance of BLIP-2 above chance on a VQA reformulation of the challenging Winoground task.
@article{Khan2023Exploring2310,
title={Exploring Question Decomposition for Zero-Shot VQA},
author={Khan, Zaid and Kumar BG, Vijay and Schulter, Samuel and Chandraker, Manmohan and Fu, Yun},
journal={arXiv preprint arXiv:2310.17050},
year={2023},
}