|
Zaid Khan I'm a 2nd-year PhD student at Mohit Bansal's group (MURGe Lab) at UNC Chapel Hill, supported by a DoD NDSEG fellowship. Most recently, I was a research intern at Ai2 working with Tanmay Gupta, Luca Weihs, and Ranjay Krishna. Before joining UNC, I was a student researcher in the Media Analytics Group at NEC Laboratories America under Manmohan Chandraker. I completed my BS+MS at Northeastern, where I worked with Raymond Fu. |

|
News
- [May 2026] New preprints: selective outcome forecasting in evolutionary kernel search (GPU Forecasters), uncertainty-aware belief states for long-horizon agents (Agent-BRACE), long-horizon memory evals (MINTEval), and dense token-level RL rewards for reasoning (AVSD).
- [Apr 2026] Two new preprints: ToM-SB (an environment where defender LLMs learn via RL to fool attackers seeking sensitive information) and Cog-DRIFT (adaptive curriculum reformulation that improves exploration on hard reasoning problems).
- [Jan 2026] Papers on neurosymbolic world models for complex environments and data recipes for reasoning models have been accepted to ICLR 2026!
- [Nov 2025] We've released PRInTS, the first reward model for long-horizon information seeking agents.
- [Oct 2025] Honored to be awarded a DoD NDSEG fellowship! 🇺🇸💫
- [Oct 2025] Selected as a NeurIPS 2025 Top Reviewer!
- [Oct 2025] One Life to Learn is out! We infer probabilistic world models in Python code for unknown, complex stochastic environments and use them for planning / simulation. Twitter thread
- [Jul 2025] UTGen has been accepted to CoLM 2025!
- [Jun 2025] OpenThoughts3 is released! It's a dataset of 1.2M reasoning traces + problems that results in a SOTA open-data reasoning model. See the blog for more details!
- [Apr 2025] EFAGen is out! EFAGen infers the data-generating abstraction underlying a static math problem as a program, and executes it to generate diverse, verifiable problem variants.
- [Feb 2025] MutaGReP is out! Let an LLM explore a repo to find a plan for a complex user request you give it. Tree search + LLM-guided mutations + code retrieval + planning.
- [Feb 2025] DataEnvGym has been accepted as a spotlight presentation at ICLR 2025!
- [Oct 2024] DataEnvGym is out! Can we automate the process of generating data to improve a model on diverse, open-ended tasks, based on automatically-discovered model weaknesses? DataEnvGym is a testbed for data-generation agents + teaching environments. Twitter thread
- [Mar 2024] Becoming a member of Mohit Bansal's group (MURGe-Lab) at UNC Chapel Hill as a PhD student, where I'll be working on multimodal agents, grounded language reasoning, and other exciting vision/language topics!
- [Feb 2024] Two papers accepted to CVPR 2024, on self-training agents to solve computer vision tasks via program synthesis (summer internship work with NEC Laboratories) and black-box predictive uncertainty for multimodal LLMs.
- [Feb 2024] Joining the PRIOR team at AllenAI this summer.
- [Sep 2023] 1 paper accepted to NeurIPS 2023 on improving the reasoning abilities of open multimodal LLMs with question decomposition. (Collaboration with NEC Laboratories America).
- [Aug 2023] Received a fellowship award from NEC Laboratories America.
- [Jun 2023] 1 paper accepted to CVPR 2023 on self-training with synthetic data for visual question answering. (Summer internship work with NEC Laboratories America).
- [Jun 2023] Joining the Media Analytics Group of NEC Laboratories America in San Jose again this summer to work on agentic foundation models for computer vision.
- [May 2023] Completed my Masters in CompE (concentration in Computer Vision and Learning Algorithms) at Northeastern University at Raymond Fu's lab.
- [Jan 2023] 1 paper accepted to ICLR 2023 on efficient vision-language pretraining.
- [Jul 2022] 1 paper accepted to ECCV 2022 on data-efficient vision-language alignment (collaboration with NEC Laboratories America).
- [Feb 2022] Joining the Media Analytics Group of NEC Laboratories America in San Jose this summer.
- [Jul 2021] 1 paper (oral) accepted to ACM Multimedia 2021 on using language models for multimodal affective computing.
- [May 2021] Received Northeastern's 2021 Outstanding Graduate Student Award!
- [Feb 2021] 1 paper accepted to FAccT 2021 on why racial categories don't work for fair computer vision. Media Coverage: Scroll.IN, News@Northeastern reporting
- [Sep 2020] Becoming a full-time MS student at Northeastern after wrapping up a 2-year stint at Roadie.
BackgroundBefore graduate school, I spent ~3 years as an early member of the engineering / data science organizations at two high growth startups: Roadie (acquired by UPS for $500m) and OneTrack.AI as software engineer, where I led efforts to scale data infrastructure to match growth, and worked on a range of challenging problems, including embedded deep learning, fault-tolerant distributed systems, realtime adaptive pricing, and data pipelines for time series and computer vision tasks. Outside of research, I lift weights, read (here's my goodreads profile), watch mixed martial arts, and sometimes wonder whether randomness is real. |
Current ResearchEnvironments + World Models
Exploration
Reinforcement Learning
Reasoning
Agents
Code Generation
Synthetic Data
Prior Research
|
PublicationsPapers where I'm a are marked; some are highlighted. |
|
GPU Forecasters: Language Models as Selective Surrogates for Kernel Runtime Optimization
Zaid Khan, Justin Chih-Yao Chen, Jaemin Cho, Elias Stengel-Eskin, Mohit Bansal arXiv, 2026 code / arXiv Can a reasoning LLM act as an approximate world model of a GPU? We train an LLM surrogate to forecast a kernel's runtime by reasoning about its code, then use RL to teach it what it doesn't know, so it sends only the kernels it can't reason about to a real GPU. In evolutionary kernel search, leaning mostly on the cheap surrogate and only selectively on the GPU finds faster kernels than the GPU alone, since the same budget explores far more of the program space. |
|
AVSD: Adaptive-View Self-Distillation by Balancing Consensus and Teacher-Specific Privileged Signals
Duy Nguyen, Hanqi Xiao, Archiki Prasad, Zaid Khan, Anirban Das, Austin Zhang, Sambit Sahu, Hyunji Lee, Elias Stengel-Eskin, Mohit Bansal arXiv, 2026 code / arXiv We've been working on a way to get better on-policy token-level rewards for LLMs + RL! Self-distillation gives token-level rewards, using divergence against a teacher policy given privileged info (i.e true final answer). What if you could use multiple forms of privileged info? |
|
MINTEval: Evaluating Memory under Multi-Target Interference in Long-Horizon Agent Systems
Hyunji Lee, Justin Chih-Yao Chen, Joykirat Singh, Zaid Khan, Elias Stengel-Eskin, Mohit Bansal arXiv, 2026 code / arXiv Continually updated envs (e.g. Git repo histories, evolving docs) are central to knowledge work. Reasoning about these requires long context understanding + resolving temporally distributed / interfering changes to the env state. How well do LLM agents / memory systems do? |
|
Agent-BRACE: Decoupling Beliefs from Actions in Long-Horizon Tasks via Verbalized State Uncertainty
Joykirat Singh, Zaid Khan, Archiki Prasad, Justin Chih-Yao Chen, Akshay Nambi, Hyunji Lee, Elias Stengel-Eskin, Mohit Bansal arXiv, 2026 code / arXiv How can LLM agents solve long-horizon tasks or explore an environment with many details while using only a fixed amount of context window? In Agent-BRACE, we use RL to build+use belief states that decompose into natural-language claims about the world and their epistemic uncertainty. |
|
Playing Along: Learning a Double-Agent Defender for Belief Steering via Theory of Mind
Hanqi Xiao*, Vaidehi Patil*, Zaid Khan, Hyunji Lee, Elias Stengel-Eskin, Mohit Bansal arXiv, 2026 code / arXiv ToM-SB is an environment where defender LLMs compete against attacker LLMs seeking sensitive information. To win, the defender must fool the attacker into leaving with the wrong information. RL in ToM-SB results in bidirectional emergence of theory-of-mind (ToM) and fooling ability. * Equal contribution |
|
Cog-DRIFT: Exploration on Adaptively Reformulated Instances Enables Learning from Hard Reasoning Problems
Justin Chih-Yao Chen, Archiki Prasad, Zaid Khan, Joykirat Singh, Runchu Tian, Elias Stengel-Eskin, Mohit Bansal arXiv, 2026 code / arXiv How do we enable RLVR on hard problems where rollouts yield zero reward? Imitating expert trajectories is off-policy; instead, we reformulate each hard problem into a multi-level curriculum. Skills learned on the easier variants transfer back to the hard set where standard RLVR fails. |
|
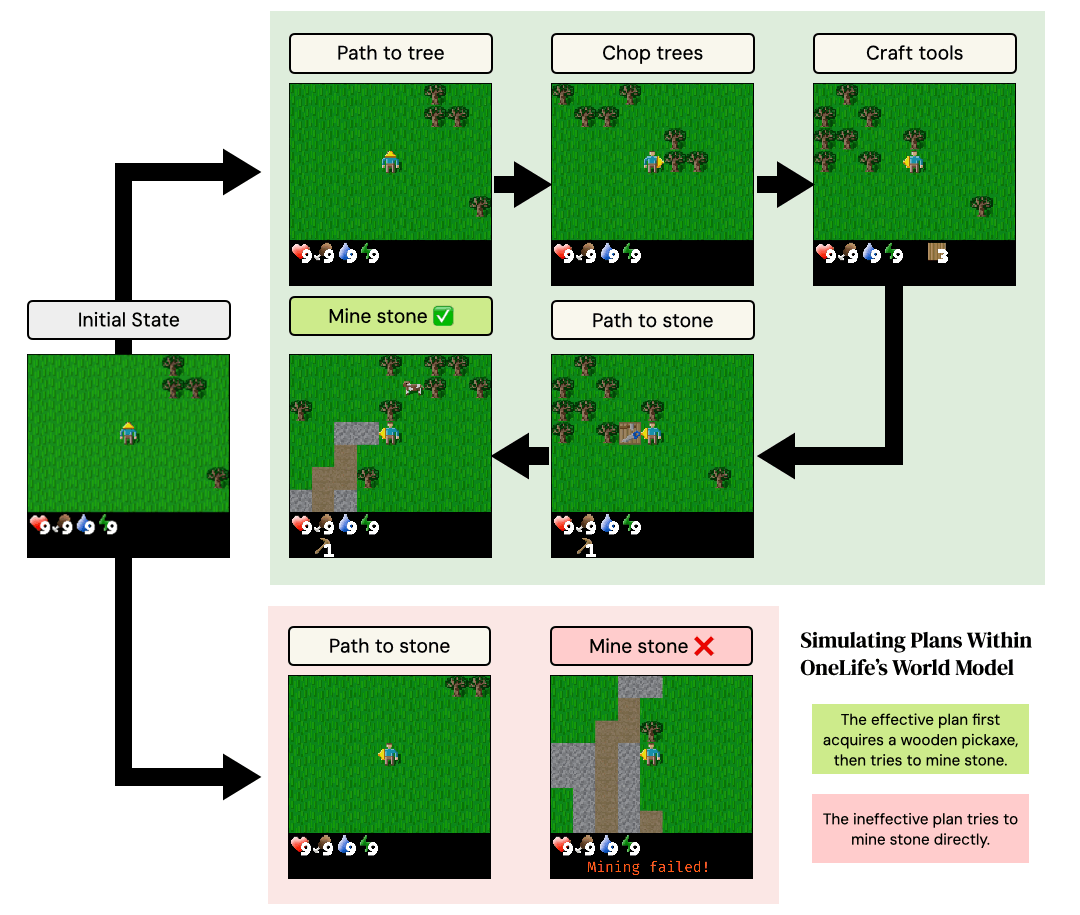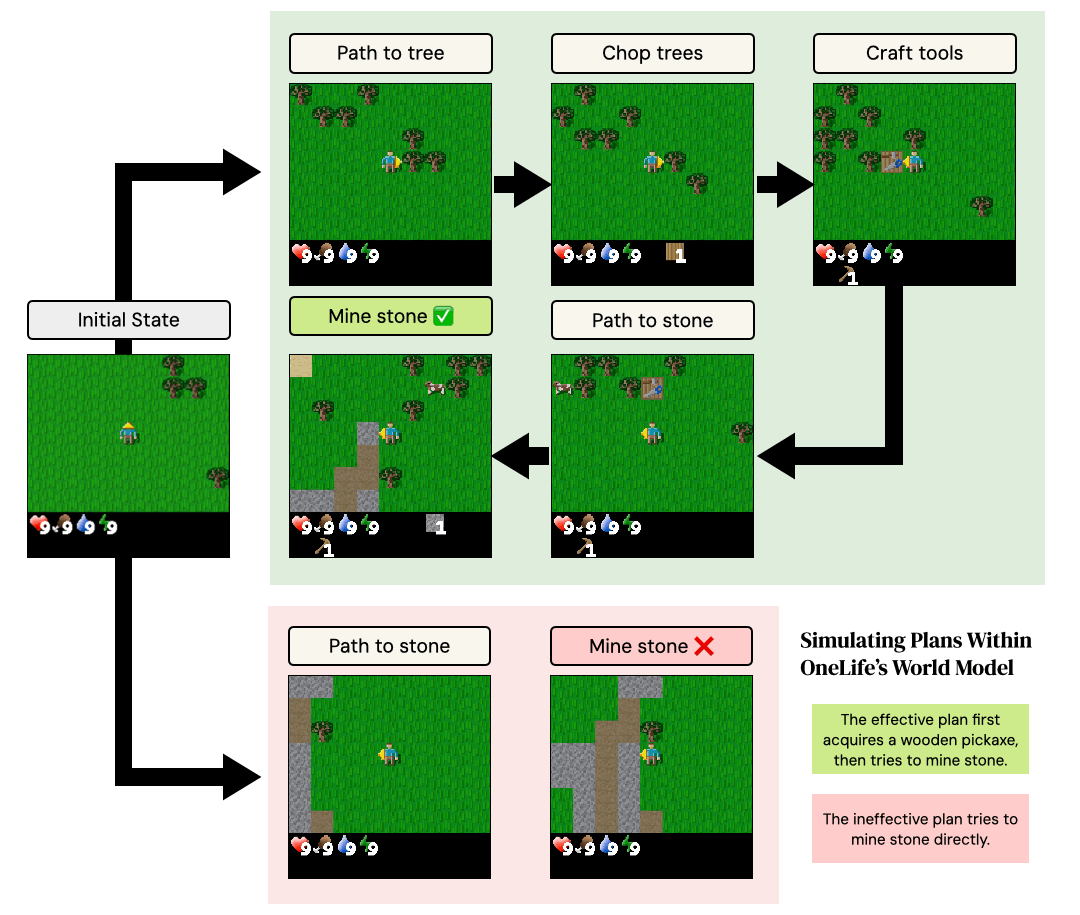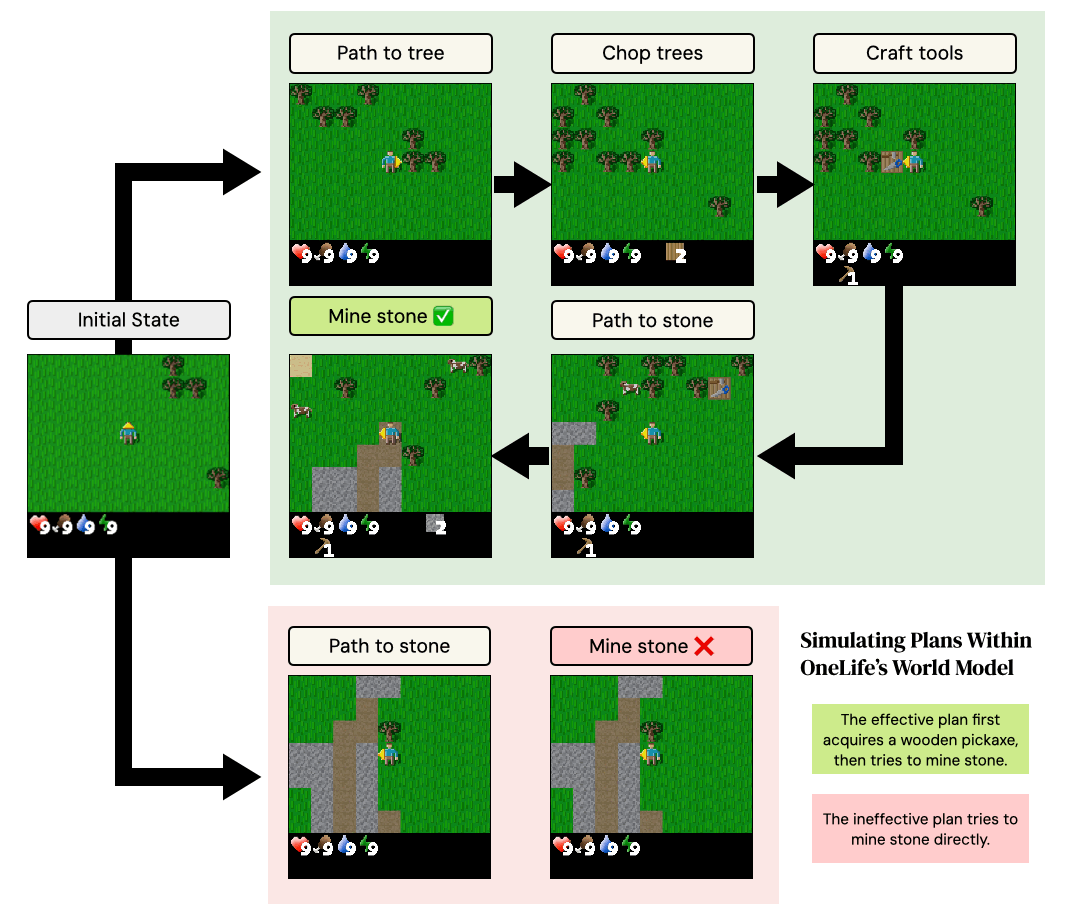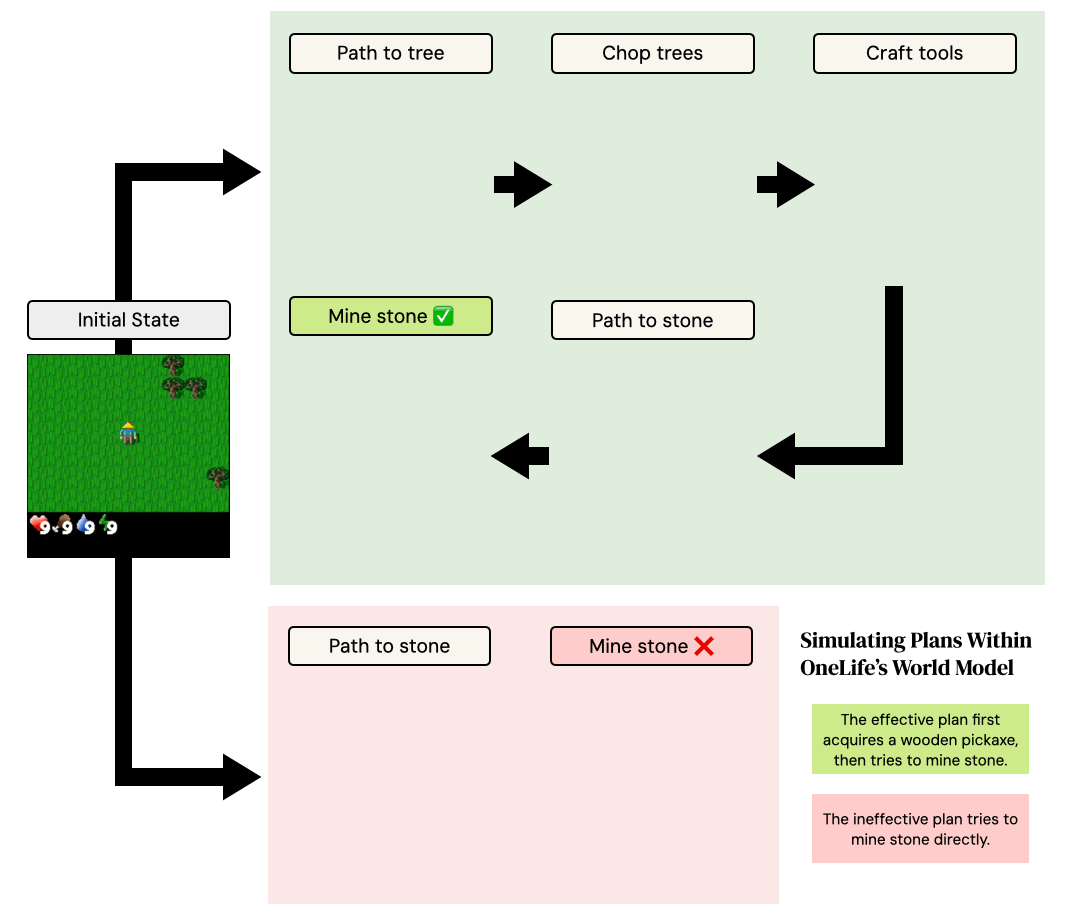
One Life to Learn: Inferring Symbolic World Models for Stochastic Environments from Unguided Exploration
Zaid Khan, Archiki Prasad, Elias Stengel-Eskin, Jaemin Cho, Mohit Bansal ICLR, 2026 project page / arXiv How can an agent reverse engineer the underlying laws of an unknown, hostile & stochastic environment in "one life", without millions of steps + human-provided goals / rewards? We infer a world model in Python for an unknown environment from a single episode! |

|
OpenThoughts: Data Recipes for Reasoning Models
OpenThoughts team (including yours truly) ICLR, 2026 Oral arXiv / openthoughts.ai The fully-open OpenThoughts3 dataset consists of 1.2M reasoning traces and problems constructed by a pipeline designed through 1,000+ controlled experiments taking 40k H100/A100 hours. The resulting OpenThinker3-7B model achieves state-ofthe-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond – improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B model. |
|
PRInTS: Reward Modeling for Long-Horizon Information Seeking
Jaewoo Lee, Archiki Prasad, Justin Chih-Yao Chen, Zaid Khan, Elias Stengel-Eskin, Mohit Bansal ACL, 2026 arXiv / code A generative Process Reward Model for long-horizon information seeking. PRINTS learns to verbally estimate the information gain of tool calls, enabling a 4B model to effectively guide 30B+ agents through noisy, complex web search tasks like GAIA Level 3. |
|
Executable Functional Abstractions: Inferring Generative Programs for Advanced Math Problems
Zaid Khan, Elias Stengel-Eskin, Archiki Prasad, Jaemin Cho, Mohit Bansal arXiv, 2025 project page / arXiv What if we could transform advanced math problems into abstract programs that can generate endless, verifiable problem variants? EFAGen uses test-time search with execution feedback to infer executable functional abstractions (EFAs) in Python for diverse math problems, including Olympiad-level problems. |

|
MutaGReP: Execution-Free Repository-Grounded Plan Search for Code-Use
Zaid Khan, Ali Farhadi, Ranjay Krishna, Luca Weihs, Mohit Bansal, Tanmay Gupta arXiv, 2025 project page / arXiv Neural tree search for repo-level code-use planning. MutaGReP explores plan space through LLM guided mutations, while grounding the plan to functionality in the codebase using a symbol retriever. |
|
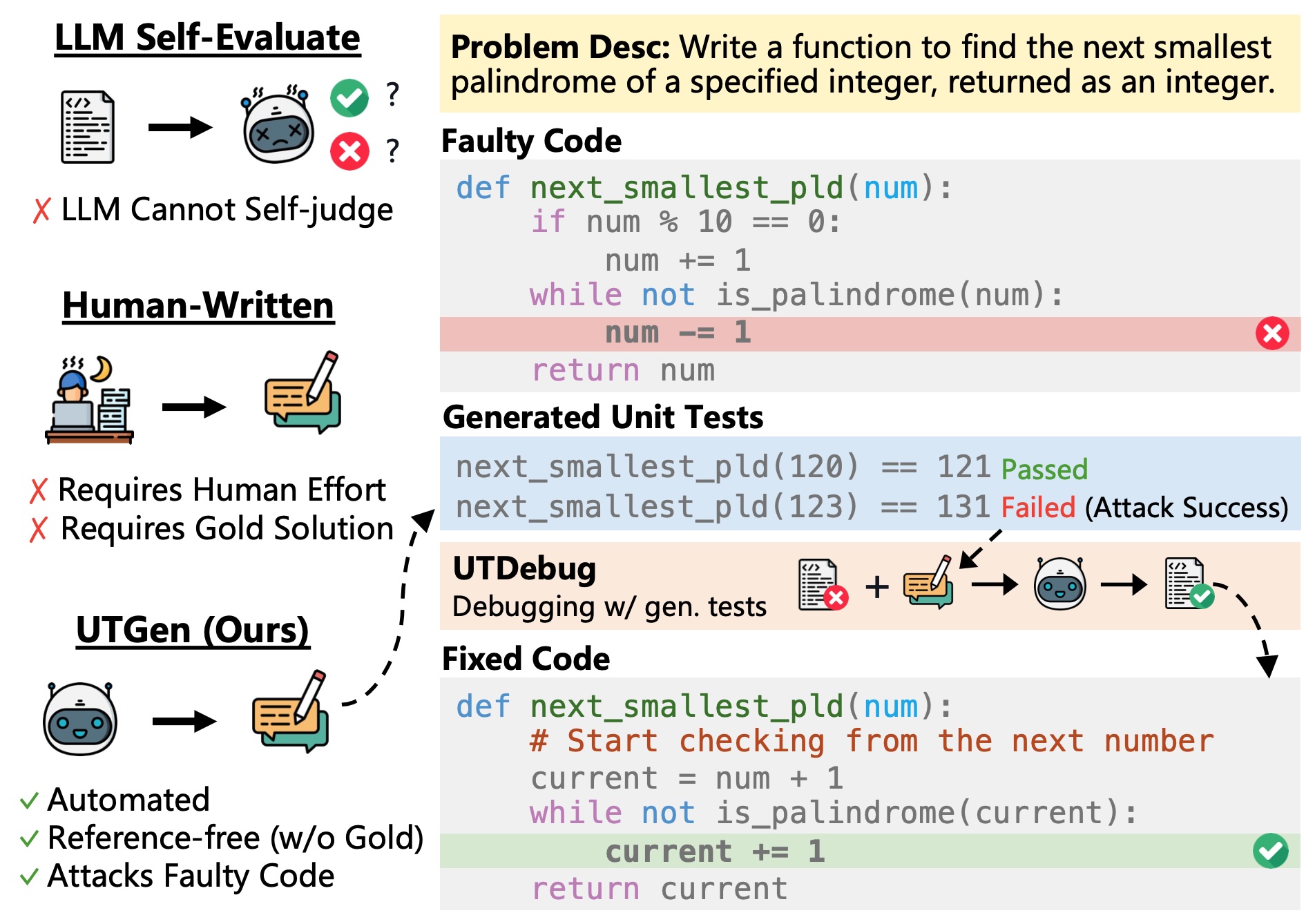
Learning to Generate Unit Tests for Automated Debugging
Archiki Prasad*, Elias Stengel-Eskin*, Justin Chih-Yao Chen, Zaid Khan, Mohit Bansal CoLM, 2025 code / arXiv Testing is a critical part of software engineering — what if we could automatically discover inputs which break your code? We show how to train SLMs (Qwen2.5-7B + Llama3.1-8B) to generate unit tests that break code and are useful for debugging. * Equal contribution |
|
DWIM: Towards Tool-aware Visual Reasoning via Discrepancy-aware Workflow Generation & Instruct-Masking Tuning
Fucai Ke, Vijay Kumar B G, Xingjian Leng, Zhixi Cai, Zaid Khan, Weiqing Wang, Pari Delir Haghighi, Hamid Rezatofighi, Manmohan Chandraker ICCV, 2025 project page / arXiv In composable AI systems for visual reasoning, agents must reliably orchestrate noisy, black-box models as tools. We propose a method that trains the agent to perform online error recovery: it learns to identify potential failures in tool outputs and iteratively refine its queries to extract the correct information. |
|
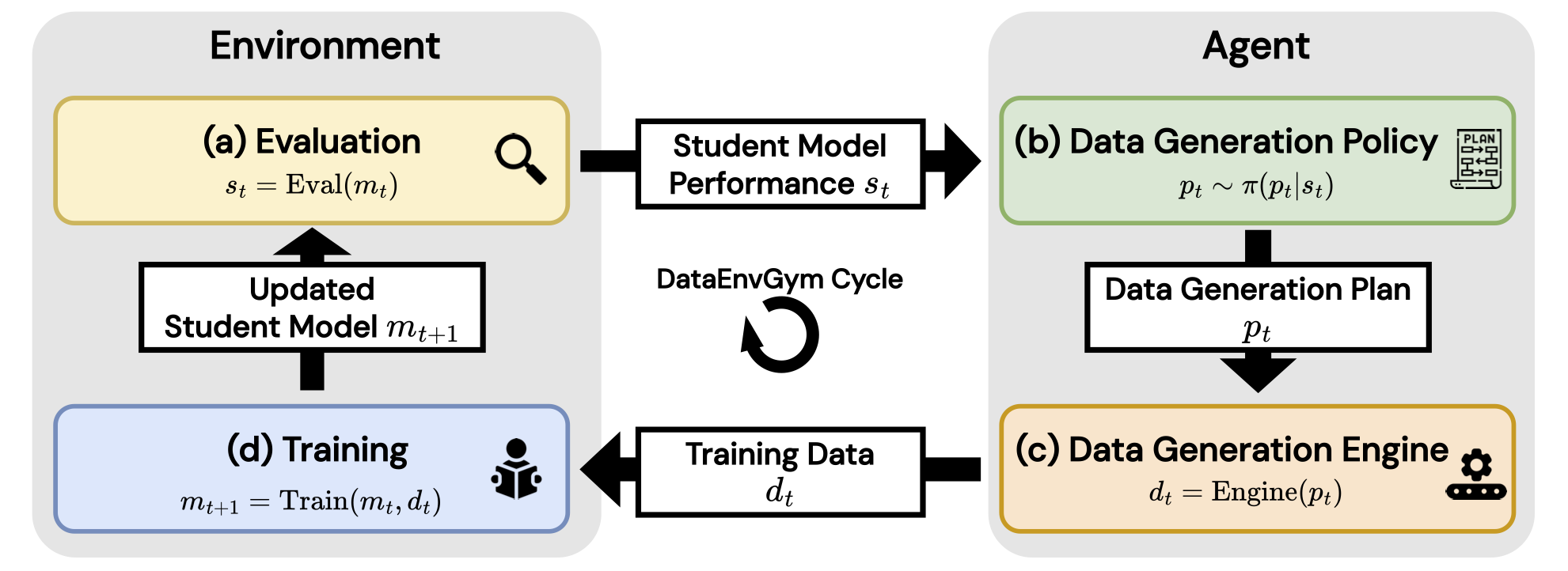
DataEnvGym: Data Generation Agents in Teacher Environments with Student Feedback
Zaid Khan, Elias Stengel-Eskin, Jaemin Cho, Mohit Bansal ICLR, 2025 Spotlight project page / arXiv A testbed for RL-style data generation agents + teaching environments to automate post-training: the process of improving a model on diverse, open-ended tasks, based on automatically-discovered model skills / weaknesses. |
|
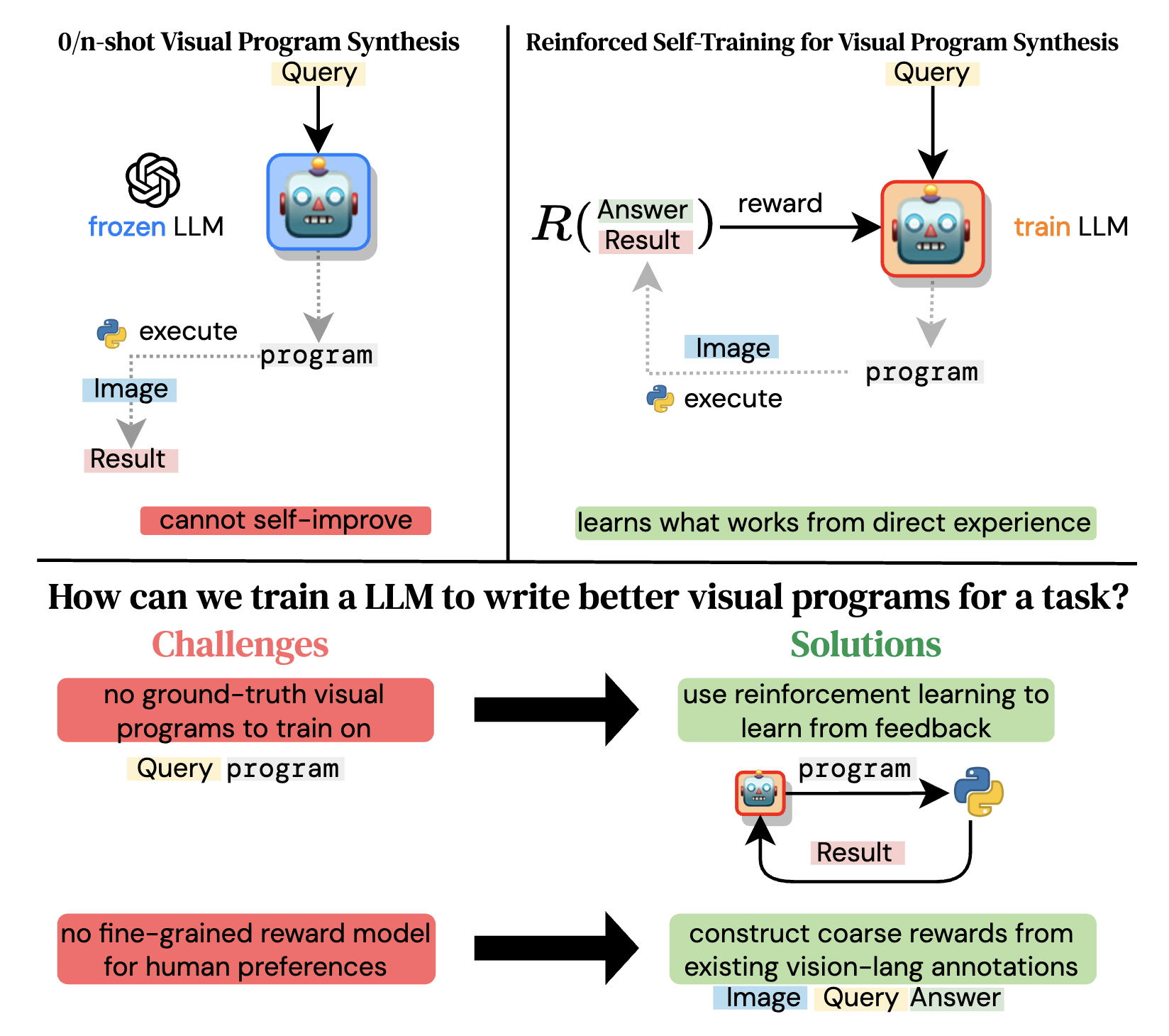
Self-Training Large Language Models for Improved Visual Program Synthesis With Visual Reinforcement
Zaid Khan, Vijay Kumar BG, Samuel Schulter, Yun Fu, Manmohan Chandraker CVPR, 2024 project page / arXiv We show how to improve the program synthesis ability of an LLM from execution feedback and apply it to create a 7B model that writes programs that orchestrate other models to solve computer vision tasks. |
|
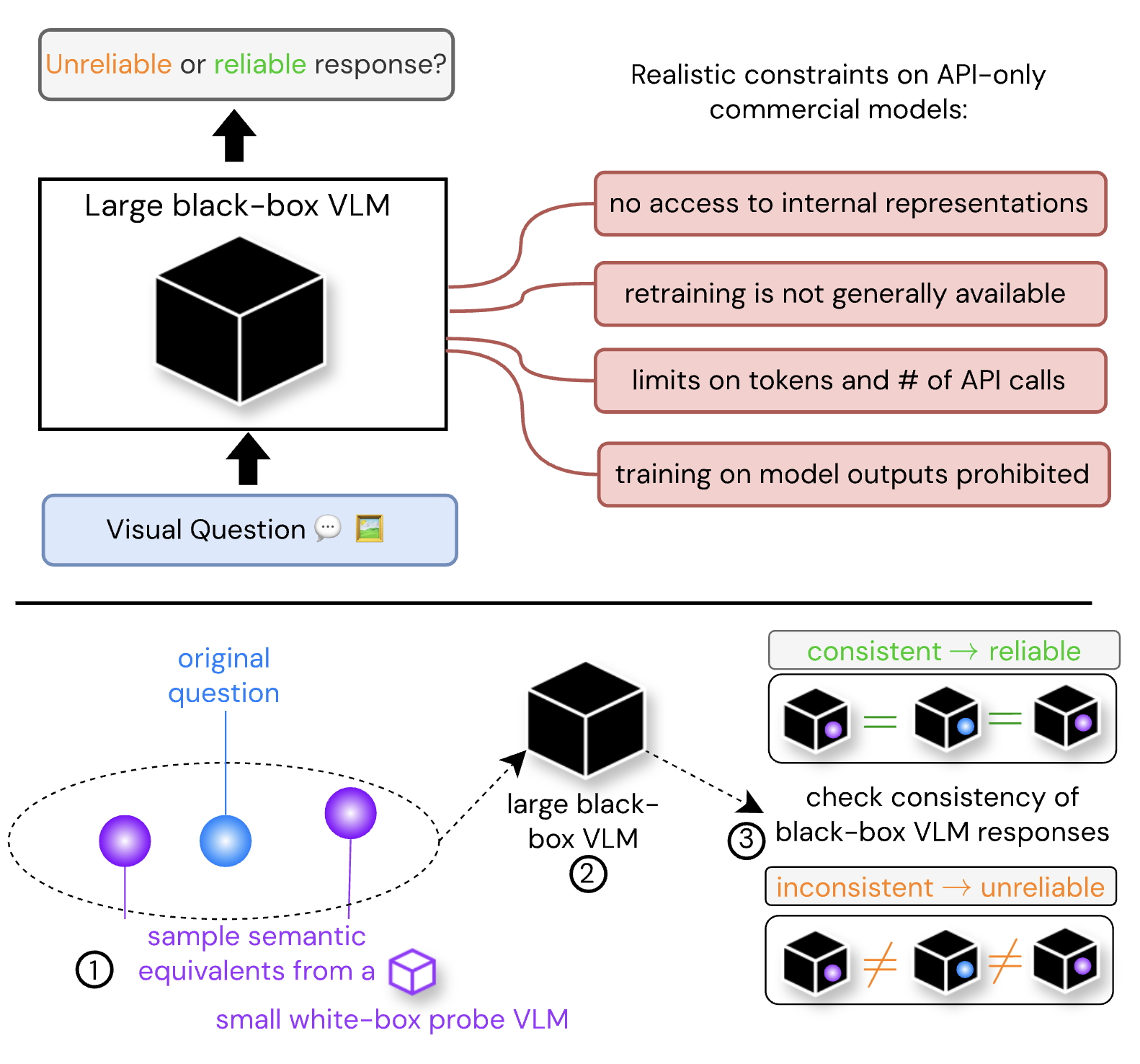
Consistency and Uncertainty: Identifying Unreliable Responses From Black-Box Vision-Language Models for Selective Visual Question Answering
Zaid Khan, Yun Fu CVPR, 2024 arXiv We show how to identify unreliable responses from multimodal LLMs by examining the consistency of their responses over the neighborhood of a visual question, without requiring access to the model's internals. |
|
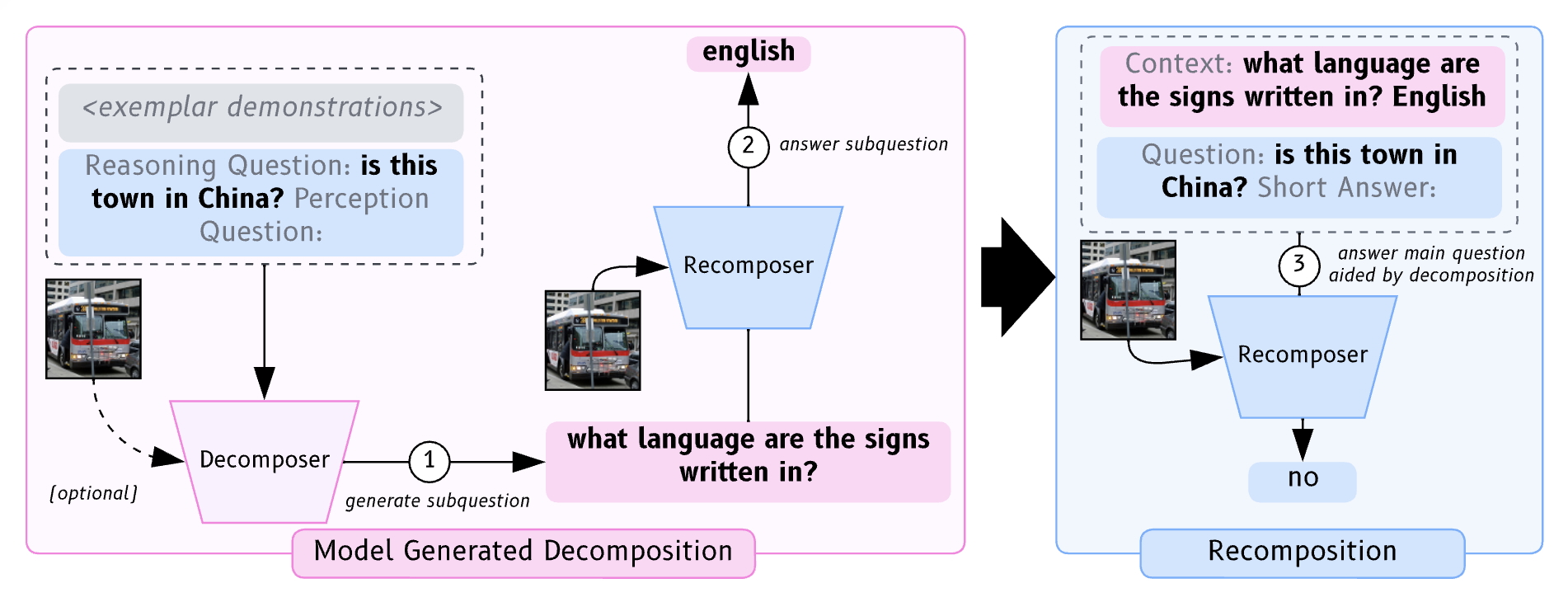
Exploring Question Decomposition for Zero-Shot VQA
Zaid Khan, Vijay Kumar BG, Samuel Schulter, Manmohan Chandraker, Yun Fu NeurIPS, 2023 project page / arXiv We show how to selectively decompose complex questions into simpler sub-questions to improve zero-shot performance on challenging multimodal reasoning tasks. |
|
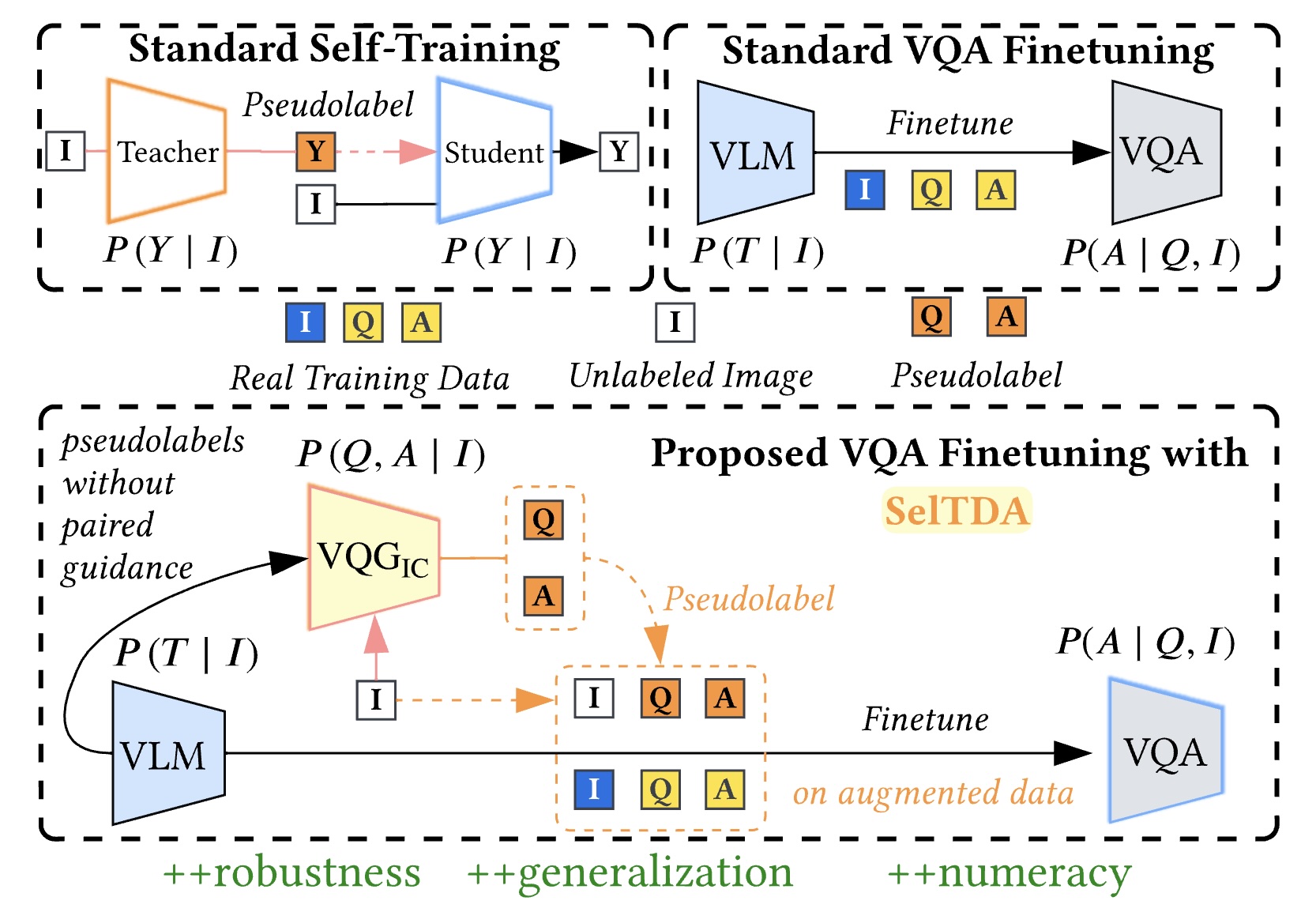
Q: How to Specialize Large Vision-Language Models to Data-Scarce VQA Tasks? A: Self-Train on Unlabeled Images!
Zaid Khan, Vijay Kumar BG, Samuel Schulter, Xiang Yu, Yun Fu, Manmohan Chandraker CVPR, 2023 code / arXiv Getting labels for a multimodal dataset can be expensive. We show how you can use unlabeled images to improve performance on data-scarce multimodal tasks. |
|
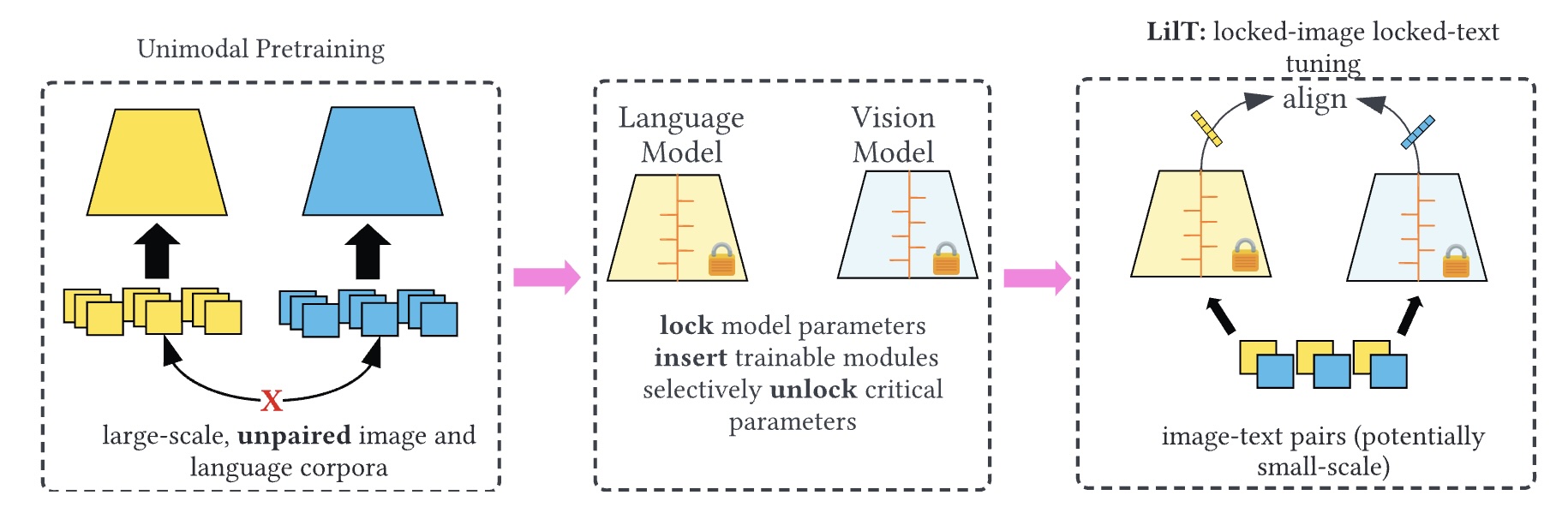
Contrastive Alignment of Vision to Language Through Parameter-Efficient Transfer Learning
Zaid Khan, Yun Fu ICLR, 2023 code / arXiv We explore creating CLIP-like models by minimally updating already-trained vision and language models, finding that updating less than 7% of parameters can match full model training. |

|
Single-Stream Multi-Level Alignment for Vision-Language Pretraining
Zaid Khan, Vijay Kumar BG, Xiang Yu, Samuel Schulter, Manmohan Chandraker, Yun Fu ECCV, 2022 project page / arXiv We demonstrate a very data-efficient way to align vision and language by learning to reconstruct each modality from the other. |
|
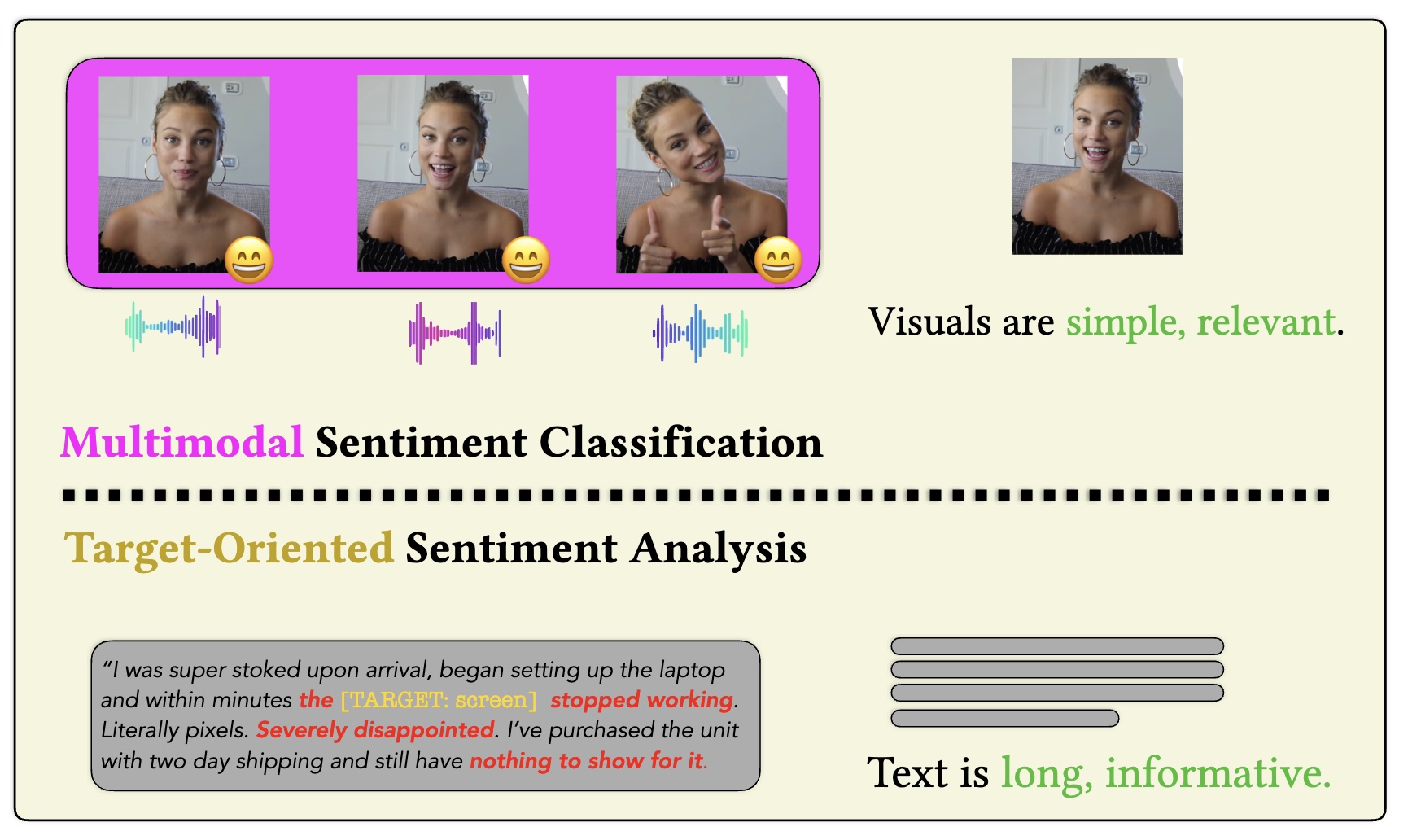
Exploiting BERT for Multimodal Target Sentiment Classification Through Input Space Translation
Zaid Khan, Yun Fu ACM MM, 2021 Oral code / arXiv Understanding the emotional content of social media posts is difficult for traditional sentiment analysis models. We show that language models do a good job of this if the post can be translated into a natural input space for them. |

|
One Label, One Billion Faces: Usage and Consistency of Racial Categories in Computer Vision
Zaid Khan, Yun Fu ACM FAccT, 2021 arXiv Are notions of algorithmic fairness based on racial categories meaningful? We study computer vision datasets that use racial categories, and empirically show that the racial categories encoded in each dataset are often highly inconsistent with each other and with human intuitions. |
|
Adapted from Jon Barron's website.. |